Bedrock dynamic pipelines cut document extraction costs
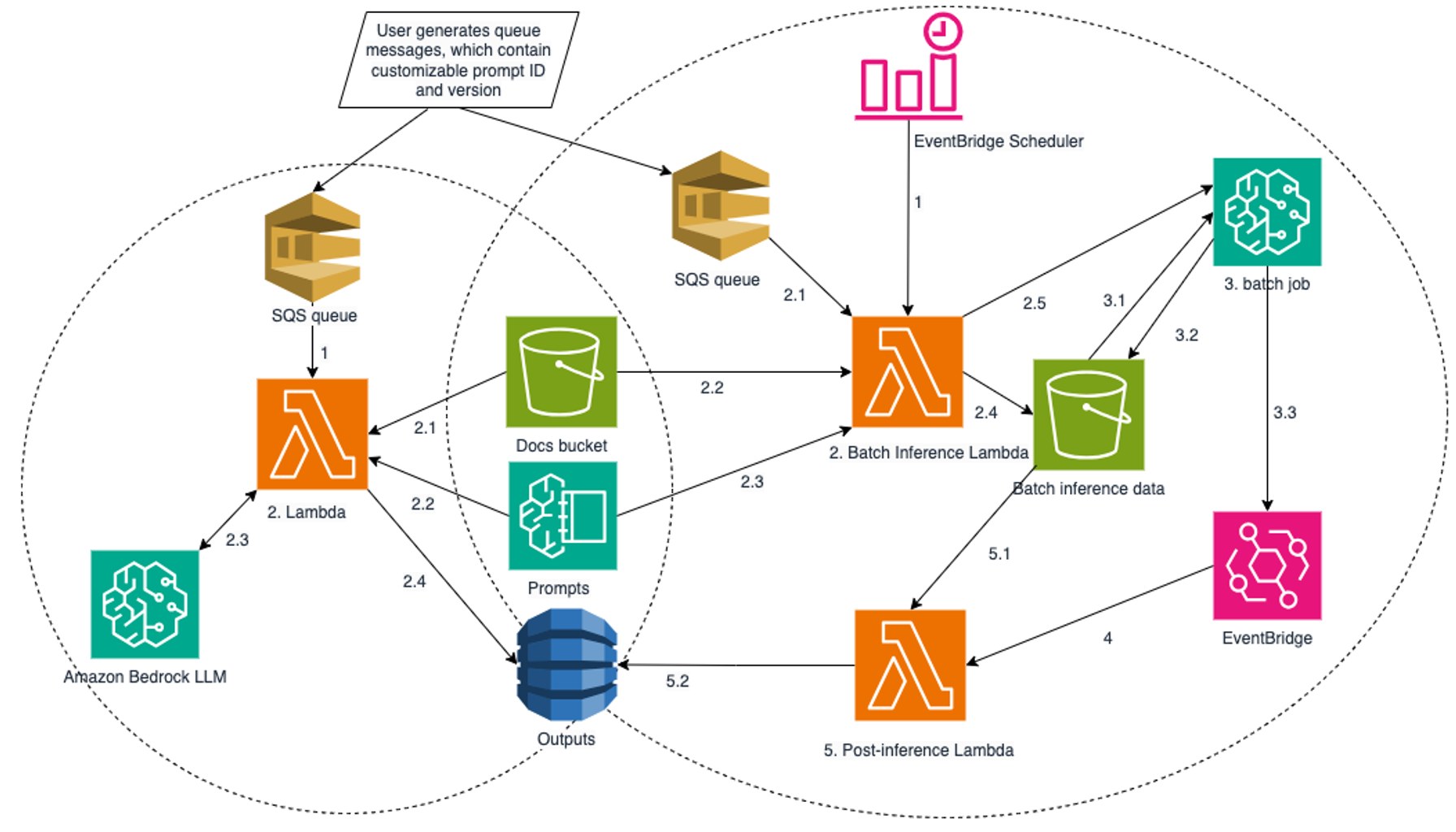
AWS Bedrock now decodes millions of scanned PDFs in seconds. The solution hinges on two inference pipelines, on demand for speed and batch for cost efficiency, that can be invoked dynamically to balance urgency and budget. The on-demand path processes documents one by one and returns results within seconds, making it ideal for time-sensitive requests. The batch path, by contrast, handles many documents at once to minimize per-document cost, a setup tailored for backlog processing.
Both pipelines support specifying the large language model and prompts at the document level, enabling a single workflow to extract data from multiple document types, whether scanned land leases, invoices, or contracts. The blog notes that this flexibility helps teams adapt to varying formats without rewriting pipelines, a practical antidote to the common brittleness of IDP systems when templates shift.
A real-world flavor comes through in the example of hundreds of millions of land lease documents stored as scan PDFs. The approach splits the work: fast on-demand in the moment for hot requests, and bulk in the background to chip away at the backlog. The architecture is designed to accommodate documents that vary in structure and quality, leveraging Bedrock Prompt Management to keep prompts aligned with changing document sets.
To lift accuracy in practical use, Bedrock Data Automation (BDA) introduces blueprints that define which fields to extract and how to extract them. The process is iterative but approachable: you provide three to ten example documents with the expected values, and BDA refines your extraction instructions automatically. The key point is that this optimization happens with no separate model fine-tuning required, yielding faster improvement cycles than traditional model-tuning workflows. By the end of the optimization step, teams can push better instructions through the same API or console they use for routine extraction tasks.
From an engineering standpoint, the method makes sense: latency and cost are orthogonal constraints that can be traded off in real time, while accuracy is improved through targeted instruction refinement rather than massive model retraining. The team reports that optimization runs take minutes rather than weeks, a meaningful delta for teams pushing toward production-grade document automation. This matters because the quality of field extraction often drifts as documents arrive from different vendors or as scans degrade; the blueprint approach provides a workable, low-friction way to chase that drift.
For practitioners, a few concrete takeaways emerge. First, start with latency budgets and document backlog: use on-demand for hot requests and batch for large queues to manage cost without sacrificing responsiveness. Second, expect and plan for data-quality issues: diverse templates, vendor variation, and scan quality are recurring failure modes, which blueprint instruction optimization is designed to address quickly. Third, governance of prompts matters: Bedrock Prompt Management helps keep extraction instructions consistent across millions of documents, reducing drift over time. Fourth, watch for the next refinements in IDP workflows: deeper integration with existing data pipelines, stronger cross-document consistency checks, and faster iteration cycles for blueprints will likely come next.
In short, AWS is turning IDP into a disciplined engineering problem with predictable tradeoffs. By combining on-demand speed, batch cost efficiency, and a blueprint-driven path to higher accuracy, Bedrock Data Automation offers a practical toolkit for teams wrestling with large-scale, heterogeneous document streams.
- Extract Data with On-demand and Batch Pipelines DynamicallyAWS Machine Learning / Primary source / Published JUN 11, 2026 / Accessed JUN 12, 2026
- Optimize blueprint extraction accuracy in Amazon Bedrock Data AutomationAWS Machine Learning / Primary source / Published JUN 11, 2026 / Accessed JUN 12, 2026