AI's growth curve: no wall in sight, Suleyman says
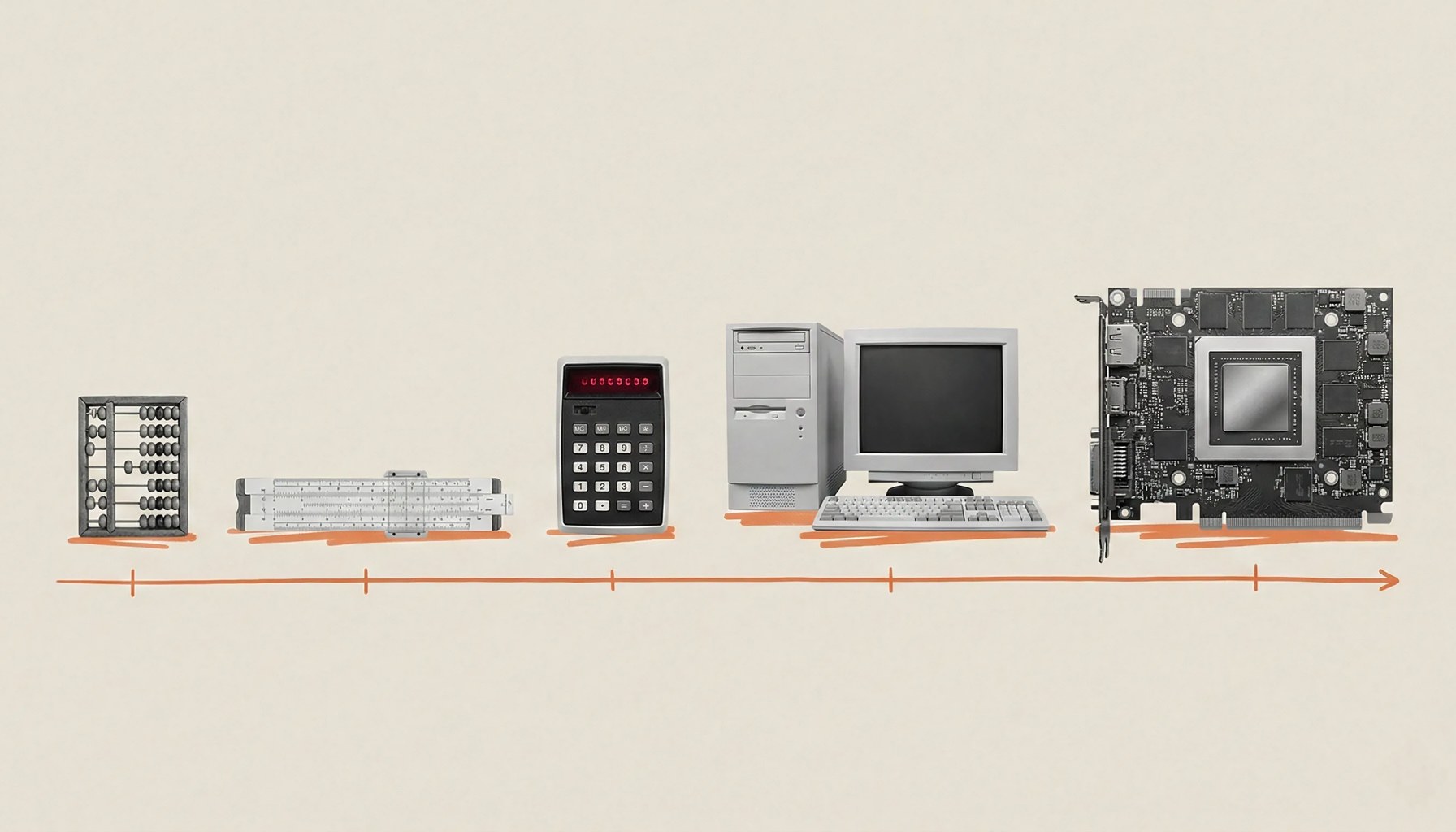
AI training data has grown by a trillion-fold, Suleyman argues.
Mustafa Suleyman, a leading voice in frontier AI, contends that the industry’s fear of an impending wall is misplaced — not because challenges disappear, but because the trendlines driving progress look inexorable: data scales and compute ramp in ways that outpace our intuition about “linear” progress. In a world where a frontiers model now ingests vastly more training data and uses orders of magnitude more compute than its predecessors, the old mental model of limits simply doesn’t apply in the way we once expected. The core insight, he argues, is that exponential growth in data and compute compounds faster than the slowing of classic hardware trends.
The takeaway is simple but profound: the exponential engine behind modern AI is not just bigger models, but a cascade of scale. Early systems ran on tens of trillions of floating-point operations; today’s frontier models run on hundreds of sextillions of FLOPs, with data inputs that balloon far beyond what older architectures could imagine. That combination — ever-larger datasets paired with ever-faster compute — creates a feedback loop where improvements compound, and bottlenecks don’t just shift; they multiply.
In Suleyman’s framing, the old “linear world” intuition — think of progress as a straight line, gradually climbed — misreads how AI evolves. He uses a vivid, almost parable-like lens: a room filled with people each with a calculator. Years ago, adding more people bought you a larger total; today, the room has become a streamlined factory where specialized hardware, software stacks, and data workflows keep the math moving without inevitable stalls. The result, in his view, is a trajectory that can endure even as traditional hype cycles ebb and flow. This is not a prophecy of perpetual ease, but a claim that the structural forces behind frontier AI are scaling in a way that can outpace common objections about data scarcity, energy, or Moore’s Law's late-stage slowdown.
The argument matters for product teams now staring at quarterly roadmaps. If the trend holds, organizations may continue to chase ever-bolder models, but the practical path to shipping remains nuanced. One takeaway for engineers: the real leverage shifts from chasing single-model arms races to optimizing data pipelines, training efficiency, and alignment workflows that can absorb billions of dollars in compute without blowing budgets. For product leaders, this suggests a continued emphasis on modular AI strategies — verticalized models, retrieval-augmented generation, and tight integration of AI services into existing platforms — rather than hoping a single miracle model will unlock every feature.
Two to four practitioner-centric takeaways follow, grounded in the landscape Suleyman describes:
The broader narrative is clear: Suleyman’s view casts the current era as a period of continued, though expensive, expansion rather than an imminent plateau. It offers a lens for teams weighing where to invest next — not just in ever-larger models, but in architectures and processes that sustain scale with responsibility.
What this means for products shipping this quarter is less about another overnight leap in model size and more about smarter data use, efficient training pipelines, and safer, more controllable AI features. If the exponential ramp persists, the best bets will be those that turn scale into reliable, value-generating software — faster, safer, and more adaptable to real user needs.
- Mustafa Suleyman: AI development won’t hit a wall anytime soon—here’s whytechnologyreview.com / Source role not classified / Published APR 08, 2026 / Accessed APR 09, 2026