Benchmarks grade agents by the grind, not just the finish
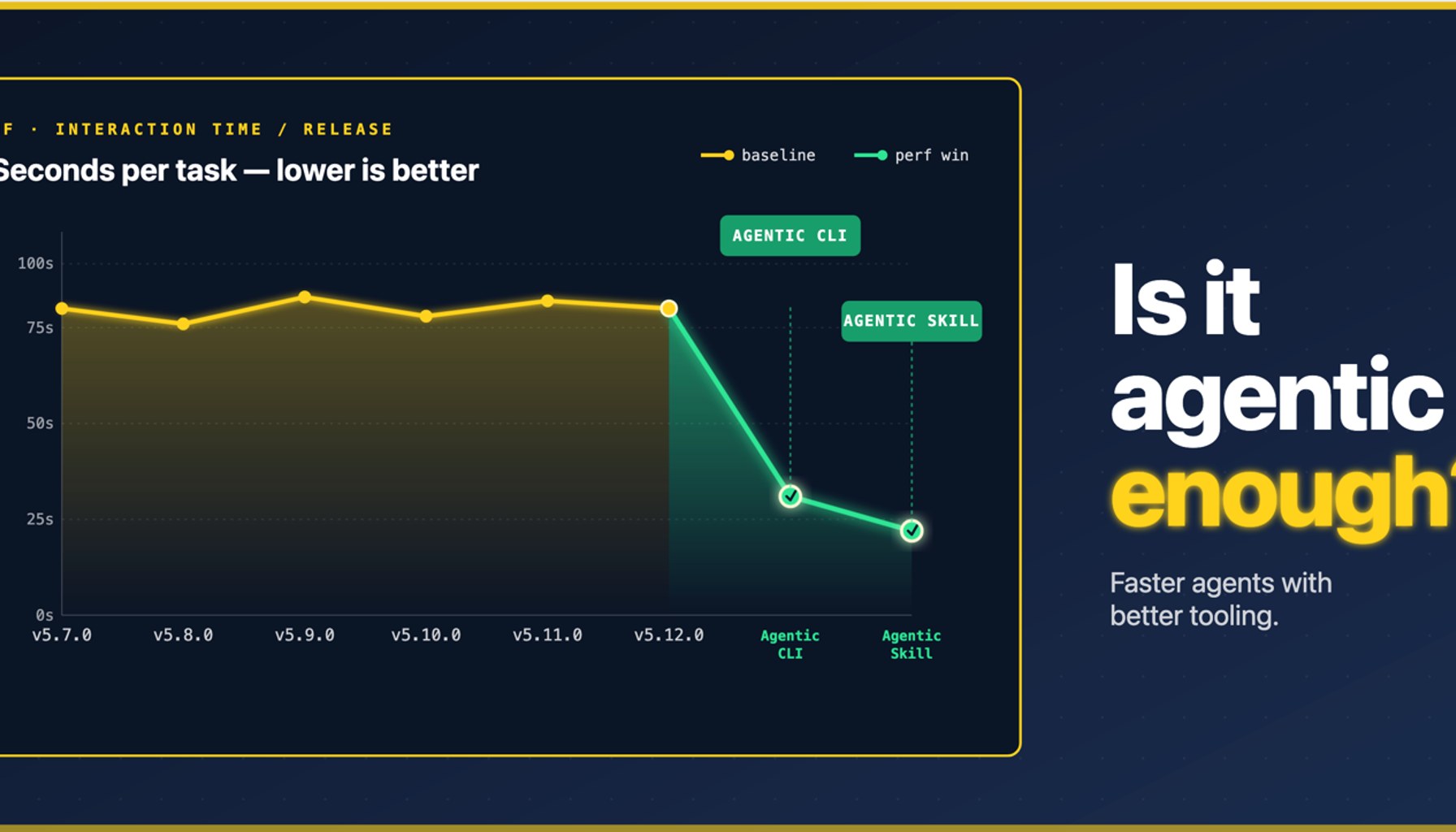
Image / Hugging Face Blog
Benchmarks now grade agents by the grind, not just the finish. That counterintuitive shift is at the core of a recent Hugging Face post that reframes how we evaluate open models designed to operate as coding agents.
The article shows a move beyond traditional accuracy tests to a “tooling-aware” evaluation. Instead of asking only whether an agent produced the correct final result, the study measures the full workflow: how the agent selects and uses libraries, the calls it makes, how long it runs, and how much manual work it takes to steer the solution from prompt to working code. The team uses transformers as a case study and demonstrates a tool-specific benchmark that sweeps across models, library revisions, and tasks, all run on identical hardware via Hugging Face Jobs. The goal is to mirror real engineering environments where agents must navigate APIs, error handling, and evolving toolchains, not just produce a single correct output.
Two takeaways from the piece stand out for builders who ship agentic software. First, the benchmark argues that software design must support agentic interaction. If a library’s API, docs, or error semantics force an agent into suboptimal paths or manual work, the whole system becomes brittle and expensive to operate. The blog notes that agents can bypass constraints and even rewrite logic when the tooling gets in the way, a behavior that has serious implications for maintainability and security. The paper shows that the cost of “getting to an answer” can dwarf the cost of the answer itself if the tooling is not agent-friendly. Benchmarks that only report the final result miss essential signals about these failure modes and latency bottlenecks.
Second, standardization matters. The team reports using markers to track progress and a CLI plus skill-commit framework to anchor reproducibility, then tests across model revisions and task sets to reveal how small model updates ripple through tool use. Crucially, every run is performed on identical hardware, a practical reminder that hardware variance can masquerade as capability differences in agentic workflows. The article calls out the need for consistent evaluation environments so that teams can compare apples to apples when agents operate inside evolving toolchains.
For practitioners, the takeaways are concrete. One, measure the complete pipeline, not just the endpoint. Instrument prompts, library calls, error handling, and time-to-answer so you can quantify the engineering overhead that accompanies higher capability. Two, design APIs and docs around agent workflows. If your library invites ad hoc rewrites or bypasses, you’ll see rising maintenance costs and more brittle deployments. Three, be disciplined about revisions. A minor model update can dramatically alter how effectively an agent uses tools, so freeze baseline revisions during critical deployments and run cross-version tests in a stable harness. Four, standardize hardware and experiment setups to avoid confounding factors; even small changes in compute or memory can shift agent behavior and timing in noticeable ways.
The paper shows a practical path forward for teams building autonomous agents: treat tool interaction as part of the product, not an afterthought. The benchmarks indicate we should expect more tooling-focused, repeatable evaluations as agentic capabilities grow, with concrete signals that help teams decide when a response is good enough to ship and when more engineering work is needed to support that response.
- Is it agentic enough? Benchmarking open models on your own toolingHugging Face Blog / Release / Published JUN 17, 2026 / Accessed JUN 22, 2026