Gaze heads steer vision language models
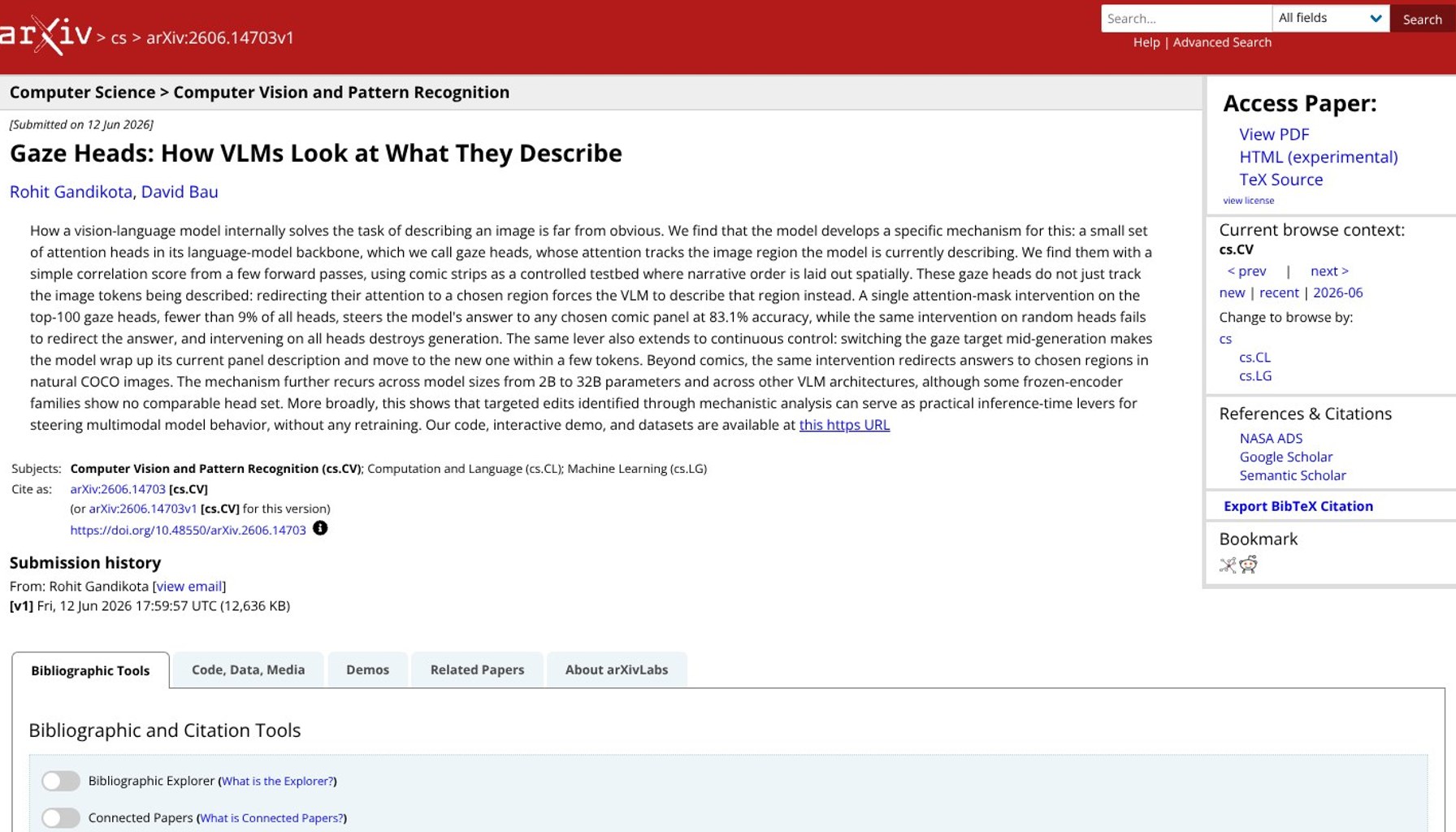
A tiny set of attention heads can force a vision language model to describe your chosen panel.
The paper shows that a small targeted mechanism inside a VLM, what the authors call gaze heads, tracks the exact image region a narrative is describing. A single attention mask intervention on the top 100 gaze heads steers the model's answer to any chosen comic panel with 83.1 percent accuracy, while intervening on random heads fails to redirect output and touching all heads destroys generation. The same lever works beyond comics, redirecting answers to chosen regions in COCO images, and the effect persists as models scale from 2 billion to 32 billion parameters. The study also finds that some frozen encoder families do not exhibit a comparable head set, suggesting the phenomenon depends on how the model's cross modal layers are wired. The authors emphasize that these are inference time edits, not retraining, opening a new practical lever for steering or testing alignment in real time. For researchers and engineers curious about how to poke a model without touching its weights, the results are especially provocative, and the team has released code, an interactive demo, and datasets at gaze.baulab.info.
The work centers on a simple but striking idea: within a vision language model, a few heads in the language model backbone develop a direct link to the image region currently being described. The authors describe how redirecting their attention to a chosen region causes the model to describe that region instead. The intervention is precise enough that it can move the description to a different panel mid generation, with only a few tokens baked in before the model pivots to the new region. Benchmarks indicate the effect holds across model sizes from 2B to 32B parameters and across multiple VLM architectures, though not universally; certain frozen encoder configurations show no comparable gaze head set. The results are presented as an example of a practical inference time lever, an alternate path to steer behavior without touching the training data or weights. The team reports that the mechanism generalizes beyond comic strips to natural images, indicating a broader, architecture level property rather than a dataset quirk.
From an engineering standpoint the finding matters because it reframes what counts as controllable during inference. If a handful of heads can dominate which region ends up described, then the process of evaluation and monitoring for model behavior must consider these localized gate points as potential levers for debugging, testing, and even misuse. The paper shows that a seemingly small subset of components can produce outsized control, which implies both opportunities and risks for product teams. In practice, this means building instrumentation to detect when attention is being redirected to a chosen region, and defining safeguards so access to such interventions is carefully governed. It also implies a design constraint: if a company relies on a frozen encoder for stability, it may miss this steering mechanism entirely, which could be a deliberate or accidental property of the chosen architecture.
Looking ahead, practitioners should watch for several near term trends. First, the ability to steer outputs without retraining invites rapid, targeted testing of alignment and failure modes in a controlled setting. Second, it highlights an actionable vulnerability surface for production models if access controls are lax. Third, it reinforces the idea that model behavior can be guided by a small set of internal tokens or heads, not by sweeping architectural redesigns. Finally, the cross model and cross domain persistence of the effect suggests a fundamental feature of multimodal alignment that warrants systematic auditing as models scale and are deployed more widely.
- Gaze Heads: How VLMs Look at What They DescribearXiv Inference Query / Primary source / Published JUN 12, 2026 / Accessed JUN 15, 2026